
时间
为了处理典型的30×覆盖度的人类全基因组,可以使用各种计算平台。某些应用需要快速的二级分析来更快地获得答案。其他应用可能会因为产生的数据量而受益于快速二级分析,而NovaSeq X嵌入式二级分析完全能够满足此类需求。
NovaSeq X每次双流动槽运行可生成多达128个或更多30×全基因组测序(WGS)样本,是真正的工厂规模仪器。不过,NovaSeq X光滑的外壳之下隐藏着一个DRAGEN,它能够即时执行二级分析,处理上一次运行的数据所需的时间往往与设置下一次运行所需的时间相当(即清洗和簇生成时间)。
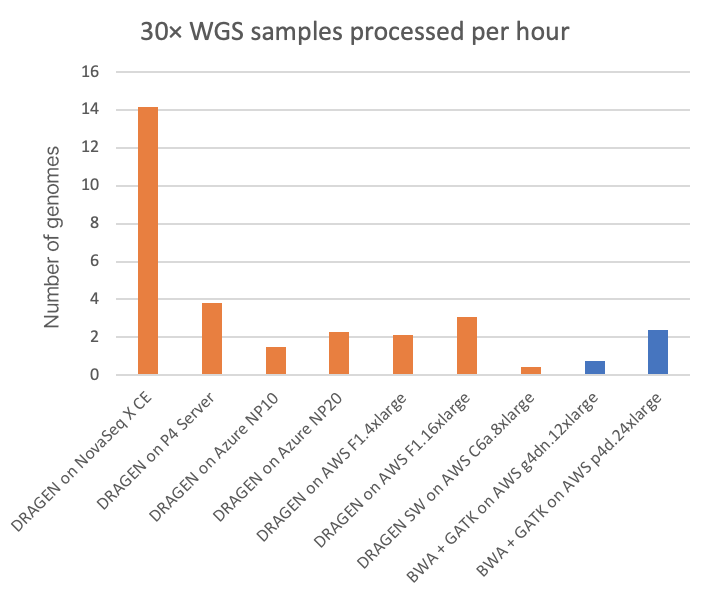
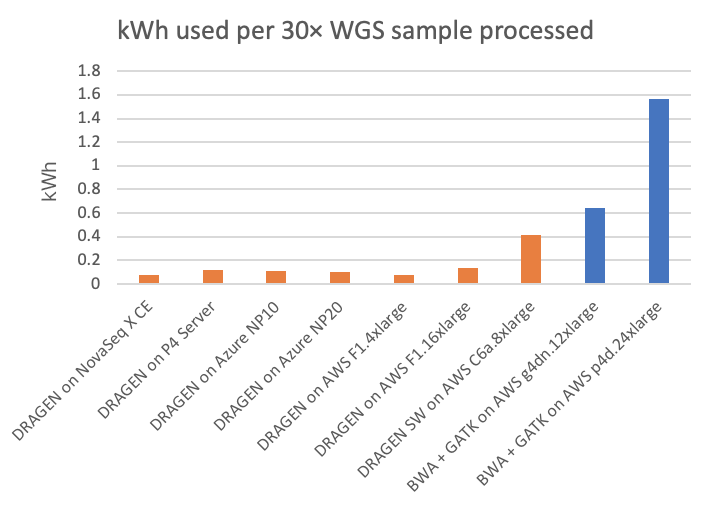
对于NovaSeq X Plus,机载DRAGEN处理功能是在双插槽AMD EPYC 7552(共有96个x86_64内核)上进行的,该处理器还配备四个Xilinx Alveo U250 FPGA卡和1.5 TB的内存。如此强大的计算能力使机载DRAGEN大约每四分钟就能向gVCF输出一次经过全面处理(每个样本BCL的分类/去重、比对read、变异检出)的30×WGS样本。在下图2中,我们将这一速度与其他一些DRAGEN实施方案以及一些GPU加速的第三方流程进行了比较。
在图2中,NovaSeq X搭载的FPGA加速嵌入式DRAGEN的分析速度分别是T4或A100 GPU云端实例的20倍或6倍左右。
请注意,在下面的图表中:
- “NovaSeq X CE上的DRAGEN”是指作为NovaSeq X仪器一部分的嵌入式、底层HPC计算。
- “P4 Server上的DRAGEN”是指可从因美纳购买的当前版本的现场专用DRAGEN服务器。
- 所有其他指标都是在Microsoft Azure和Amazon Web Services(AWS)提供的各种可公开访问的云端计算实例上运行得出的。
- 所有DRAGEN运行均涉及FPGA加速,但与“AWS C6a.8xlarge上的DRAGEN SW”相关的运行除外,这些运行使用纯软件版本的DRAGEN流程。
- BWA+GATK运行显示了AWS云端中两种不同类型的GPU实例类型,其中流程已移植到GPU并针对GPU进行了优化,以此来加快运行时间。
成本
当处理大量数据时,还必须考虑计算成本。在NovaSeq X仪器中,DRAGEN计算功能包含在仪器成本中,因此对NovaSeq X用户来说实际上是免费的。然而,如果我们将计算组件成本分摊到测序通量和仪器的预期五年寿命上,我们将得出每个30×WGS样本的成本。
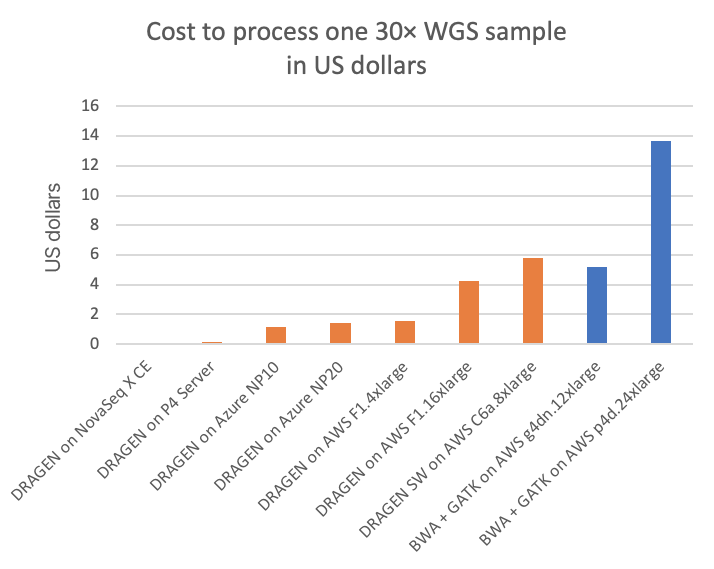
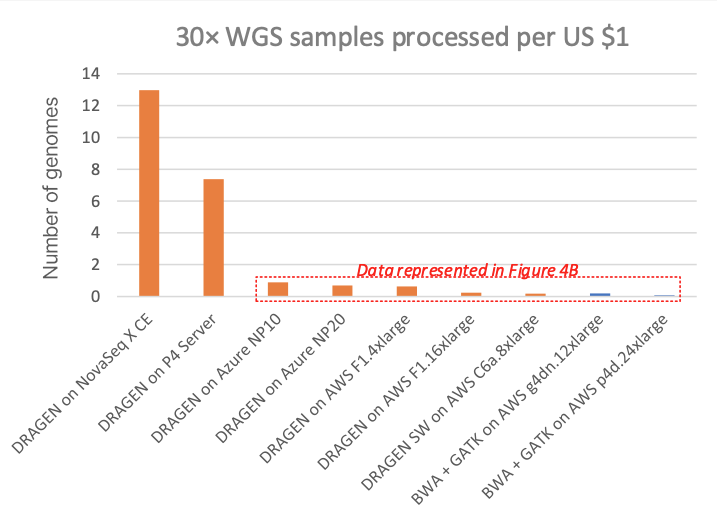
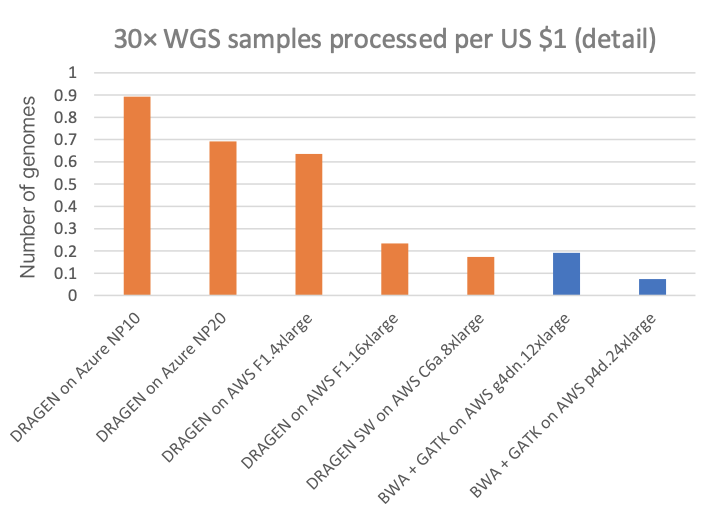
图3以单个30×WGS样本的成本为对象,将其与不同云端计算实例上的其他几种DRAGEN和第三方流程(所有列出的云端均显示“按需”定价)进行了比较。图4A显示了每美元可以处理的30×WGS样本的数量,放大图4B为图4A的详细视图,去除了专用DRAGEN硬件数据点(NovaSeq X CE和DRAGEN P4 Server的每美元样本数非常高,因此需要扩大y轴刻度以便更好地查看其他云端选项定价的细微差别)。
从图表中可以看出,NovaSeq X上搭载的FPGA加速DRAGEN的成本不到T4或A100 GPU云端实例的1/60或1/170。
能源
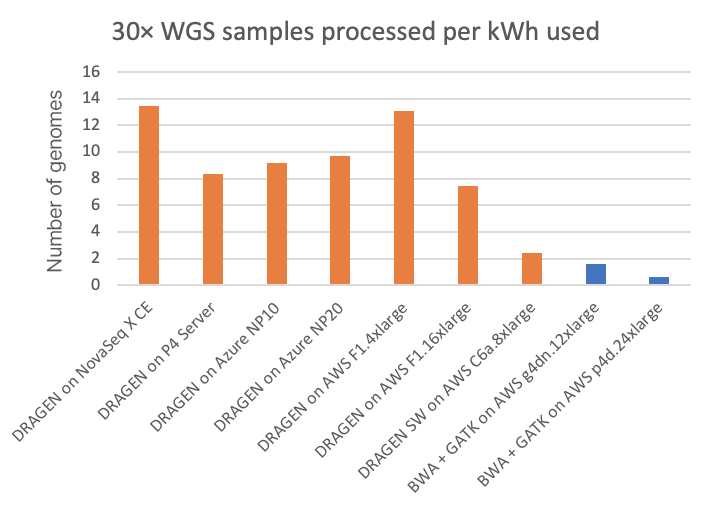
功耗是一个值得关注的因素,因为它不仅关系到环境影响和公用事业成本,而且可能会限制二级分析计算平台的外形尺寸。对于NovaSeq X CE和P4 Server DRAGEN运行,我们可以直接测量DRAGEN计算平台的功耗。在云端平台上,我们可以根据发布的系统配置来估算功耗。(亲爱的读者,如果您有更准确的云端功耗信息,请使用此处链接的表格联系我们,我们将很乐意对本文进行相应修改。)图5和图6分别显示了机载NovaSeq X DRAGEN和现场P4 DRAGEN服务器,以及在云端计算实例上运行的其他DRAGEN和第三方流程的能耗情况,分别为每个30×WGS样本的千瓦时能耗和每千瓦时能耗可处理的30×WGS样本数(30×WGS/kWh)。
从图表中可以看出,NovaSeq X上搭载的FPGA加速DRAGEN的能效优势分别是T4或A100 GPU云端实例的8倍或20倍以上。
占地面积
值得注意的是,NovaSeq X仪器只有一个标准200-240 VAC、50/60 Hz、15 A单相电源插头,测序硬件(激光器、加热器、泵等)和DRAGEN计算平台都使用该插头获取电源。此外,必须对嵌入式DRAGEN计算平台产生的热量进行一定的处理,避免对测序的化学或生物反应产生不利影响。FPGA加速DRAGEN可降低每个基因组的能耗,并可在小巧体积中实现HPC级计算能力,缩小了占地面积。
结果质量
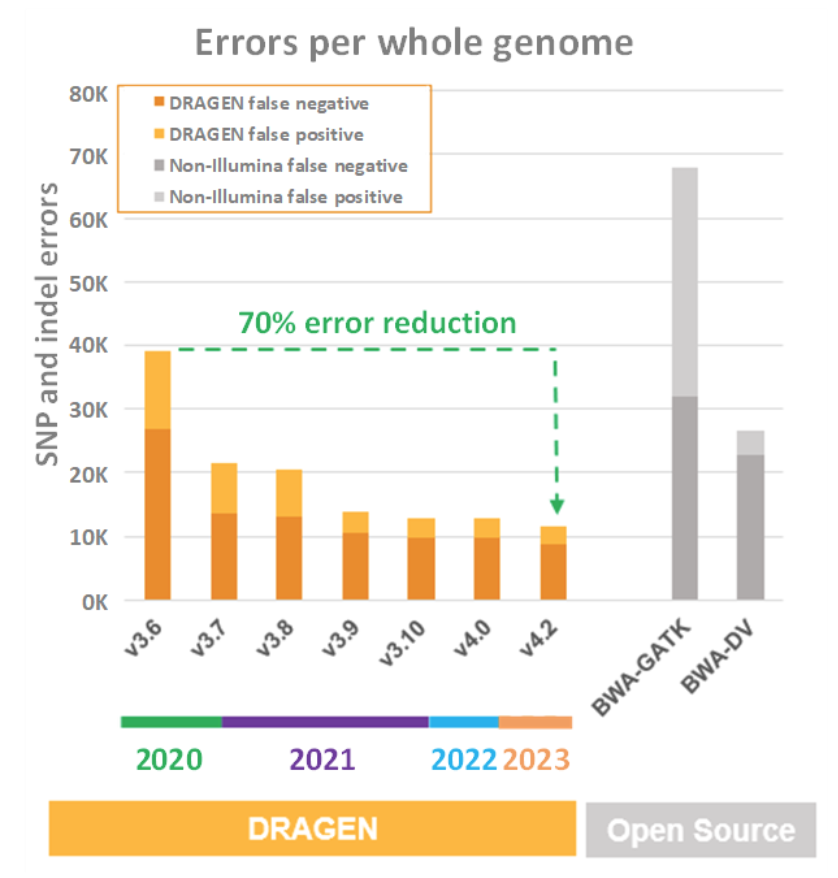
在上文关于通量、成本、功耗和占地面积的比较中,NovaSeq X机载DRAGEN计算平台都名列前茅,令人印象深刻。但这些图表并不能完全说明为什么选择FPGA来加速DRAGEN。之所以选择FPGA来加速DRAGEN,是因为FPGA在通量、成本、功耗和占地面积方面都具有优势,可以应用更多计算密集型算法,从测序仪读取的数据中获取尽可能多的有用信息。DRAGEN在这方面已经非常出色,现在正在不断超越自己,每一次DRAGEN流程的发布都在不断地提高精度、灵敏度和特异性。下图7对此进行了总结,图中显示了第三方二级分析流程(BWA+GATK和Google Deep Variant)和几代DRAGEN的假阳性和假阴性指标。
结论
CPU和GPU制造商都在不断改进与基因组学工作相关的产品,与FPGA相比,CPU或GPU编程流程所需的开发人员工作量更少。
尽管如此,因美纳的工程师们仍旧通过艰辛的努力,将基因组学流程移植到了FPGA加速平台上,而这种FPGA加速在客户关心的各项指标上都显示出了明显的优势。这反过来又为那些能够使用FPGA加速DRAGEN流程的因美纳客户带来了实实在在的好处。
关于基因组学即将面临的计算瓶颈,业内有很多说法,似乎计算成本、功耗和/或周转时间会以某种方式导致基因组学目前的进展突然放缓或停止。有了FPGA加速,这样的瓶颈似乎不存在了。 机载FPGA加速DRAGEN可以在不到5分钟的时间内全面分析30×人类基因组,计算成本不到10美分,所需的能量与推动最高效的特斯拉Model 3行驶半公里所需的能量差不多。
DRAGEN的通量、成本、功耗和占地面积等指标都是首屈一指的,令人印象深刻。更令人印象深刻的是,DRAGEN在达到这些指标的同时,还能不断提高结果质量(精度、灵敏度、特异性),比任何其他NGS二级分析流程都要出色。随着CPU、GPU和FPGA不断发展,DRAGEN团队一直在寻求最新的技术,以便为我们的用户提供更好、更准确的结果。